随笔04
关于多线程的几点补充
在理解线程的状态时,需要先了解每个对象都有的——锁池和等待池这两个概念。
锁池就是一个线程A已经占用了对象锁,其他对象想要拿到该对象锁就必须等待A释放锁,这些想拿到对象锁的线程就会进入锁池,等待和竞争锁。
等待池:假设一个线程A调用了某个对象的wait()方法,线程A就会释放该对象的锁,进入到该对象的等待池。
从上面就可以看出锁池是里的线程都是竞争锁的,而等待池里的线程已经被释放锁,等待被唤醒,所以是不会竞争该对象的锁
我们先聊下sleep和wait的区别
Sleep是Thread的静态方法,线程休眠,不会让出锁,而是到时候就继续执行。可以在程序的任何地方进行使用。
Wait是Object的方法,线程释放锁,进入等待池,等待notify()或notifyAll()唤醒,进而进入锁池,竞争锁。Wait必须是在已经持有锁的情况下去调用释放锁,不然会抛出IllegalMonitorStateException,因为锁都没,何谈释放锁呢?
接下来就是wait,notify,notifyAll()的区别,上面已经说到,调用wait就是使线程释放当前锁进入等待池,那么也不是一直等待啊,当我们需要某个线程就可以调用notify()或者notifyAll()来使线程从等待池中解放出来,进入锁池去竞争锁。所以这里就有个很重要的知识点——调用notify()或者notifyAll()是不会立即获得锁,而是去锁池竞争锁,竞争锁的情况那就不一样了,可能直接就获得锁了,也可以进入等待队列。这个也是blocked和waiting状态的区别。
对于notify()和notifyAll()大同小异,notify()是随机唤醒一个等待池中的线程进入锁池,notify()是唤醒全部线程进入锁池。当然调用notify()随机唤醒会有优先级的控制,但只是概率,不是每次都是严格按照优先级,这个是凭cpu调度的。
Redis五大基本数据类型的底层实现
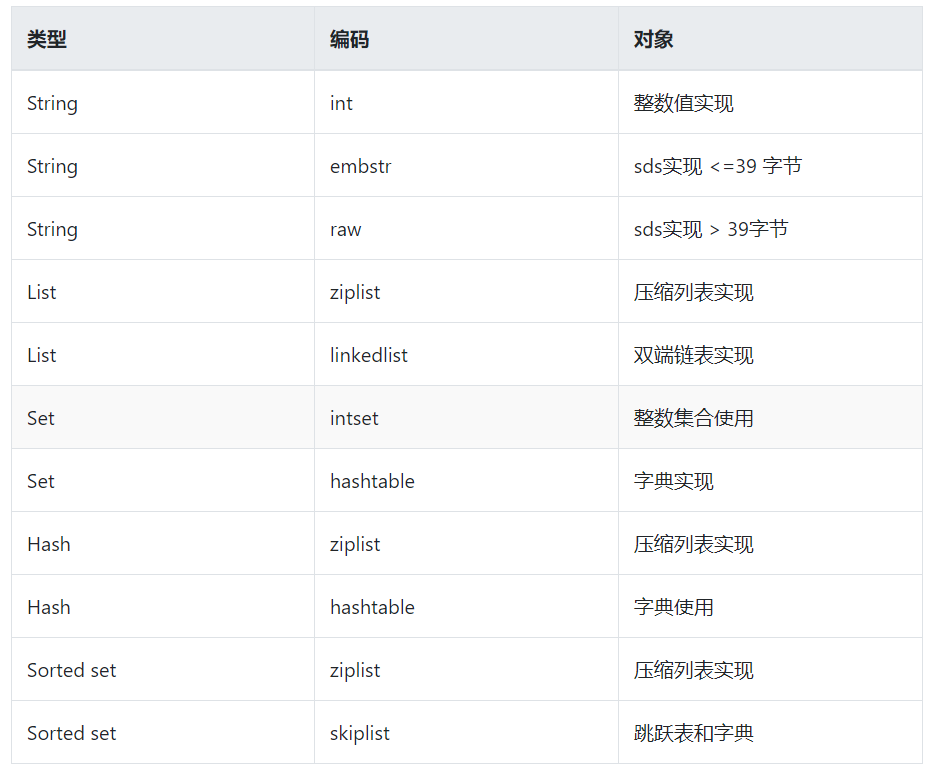
据上表可知,String的编码可以是int,embstr,raw,当输入的数值可以转换为long,那就以int的类型进行存储。对于字符类型,redis底层并不是直接使用string,而是自己实现了一个简单的动态字符串sds,c语言的string是不记录自身长度是,但sds是记录的,这样就使得获取本身字符长度的操作时间复杂度从O(n)降到O(1),对于emstr编码的范围是字符串字节小于等于39个字节,raw是大于39个字节,当然int编码也是可以在一定情况下转换为raw的,比如对int进行append操作。
List是一个有序的,可插入重复元素的链表结构,底层是ziplist或linkedlist。ziplist是一个压缩型链表,为节约内存而开发的,适用于长度较小的值,其是由连续空间组成(会保存每个值的长度信息,因此可依次找到各个值),存取效率高,占用空间小,但由于地址空间是连续的,所以修改链表需要修改地址空间。LinkedList是一个无环的双向链表,修改效率高,但每个节点都需要保留前驱和后继,占用内存大。对于两种数据结构的选择,list是以保存的字符串元素大小都小于64个字节和元素数量小于512个作为标准,两个都满足就用ziplist,一个不满足就用linkedlist。
Hash底层由ziplist或hashtable实现,ziplist底层的压缩列表,对于存储hash的对象是把同一键值对的两个节点相互紧靠,key在前,value在后,先保存的就在ziplist的表头方向,后来的就在表尾。Hashtable底层是字典实现,每个键值对都使用一个字典键值对保存,字典的键为字符串对象,保存ket,字典的值也为字符串的对象,保存键值对的值。Ziplist和hashtable的选择,当list对象满足保存的字符串元素大小都小于64个字节和元素数量小于512个,就用ziplist,否则用hashtable。上面的两个值可以在redis的配置文件中的hash、-max-zaiplist-value和hash-max-ziplist-entries进行修改。
Set的编码可以为insert或hashtable,insert使用数组作为底层实现,不会出现重复元素。Hashtable底层还是字典,只是value为空而已。Insert和hashtable的选择,当所有的元素都是整数和元素个数小于512个,就用insert否则用hashtable。
ZSet的对象编码是ziplist或者skiplist(跳表)实现,zipList编码,每个集合元素使用相邻的两个压缩列表节点保存,一个保存元素成员,一个保存元素分值,然后从小到达排序。对于跳表应该是比较陌生的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的,通俗点说就是添加了多重索引的结构。一个有序集合包含的元素数量比较多,又或者有序集合中元素的成员是比较长的字符串时,Redis就会使用跳跃表来作为有序集合健的底层实现。跳跃表实现由zskiplist和 zskiplistnode两个结构组成,其中zskiplist用于保存跳跃表信息(比如表头节点、表尾节点、长度),而zskiplistnode则用于表示跳跃表节点。Redis每个跳跃表节点的层高都是1至32之间的随机数。在同一个跳跃表中,多个节点可以包含相同的分值,但每个节点的成员对象必须是唯一的跳跃表中的节点按照分值大小进行排序,当分值相同时,节点按照成员对象的大小进行排序。
对于具体使用ziplist还是skiplist作为zet的底层,当元素数量小于128和保存的所有元素的长度都小于64个字节,就是用ziplist,否则使用跳表实现。