归并排序
归并排序(MERGE-SORT)是利用归并的思想实现的排序方法,该方法采用经典的分治策略(分治法将问题分成一些小的问题然后递归求解,而治的阶段则将分的阶段得到的各个答案拼接在一起,即为分而治之)。
实现思想
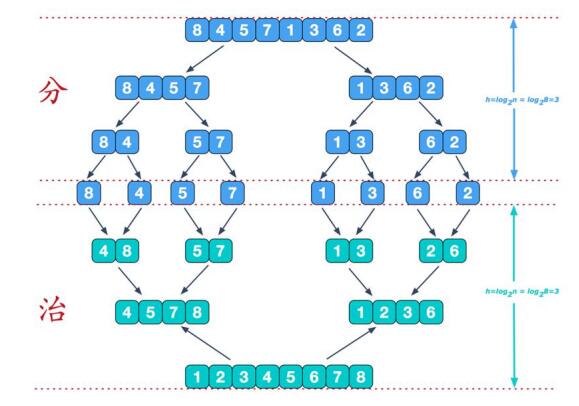
具体步骤
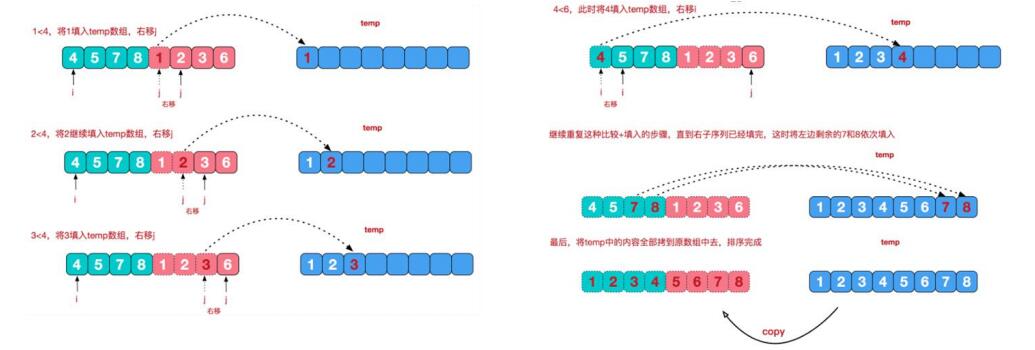
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
public static void mergeSort(int[] arr, int left, int right, int[] temp) {
if(left < right) {
int mid = (left + right) / 2;
mergeSort(arr, left, mid, temp);
mergeSort(arr, mid + 1, right, temp);
merge(arr, left, mid, right, temp);
}
}
/\*\*
\*
\* @param arr 排序的原始数组
\* @param left 左边有序序列的初始索引
\* @param mid 中间索引
\* @param right 右边索引
\* @param temp 做中转的数组
\*/
public static void merge(int[] arr, int left, int mid, int right, int[] temp) {
int i = left;
int j = mid + 1;
int t = 0;
while (i <= mid && j <= right) {
if(arr[i] <= arr[j]) {
temp[t] = arr[i];
t += 1;
i += 1;
} else {
temp[t] = arr[j];
t += 1;
j += 1;
}
}
while( i <= mid) {
temp[t] = arr[i];
t += 1;
i += 1;
}
while( j <= right) {
temp[t] = arr[j];
t += 1;
j += 1;
}
t = 0;
int tempLeft = left;
while(tempLeft <= right) {
arr[tempLeft] = temp[t];
t += 1;
tempLeft += 1;
}
}
|
注释写的很详细,这里就不做过多论述了。
基数排序
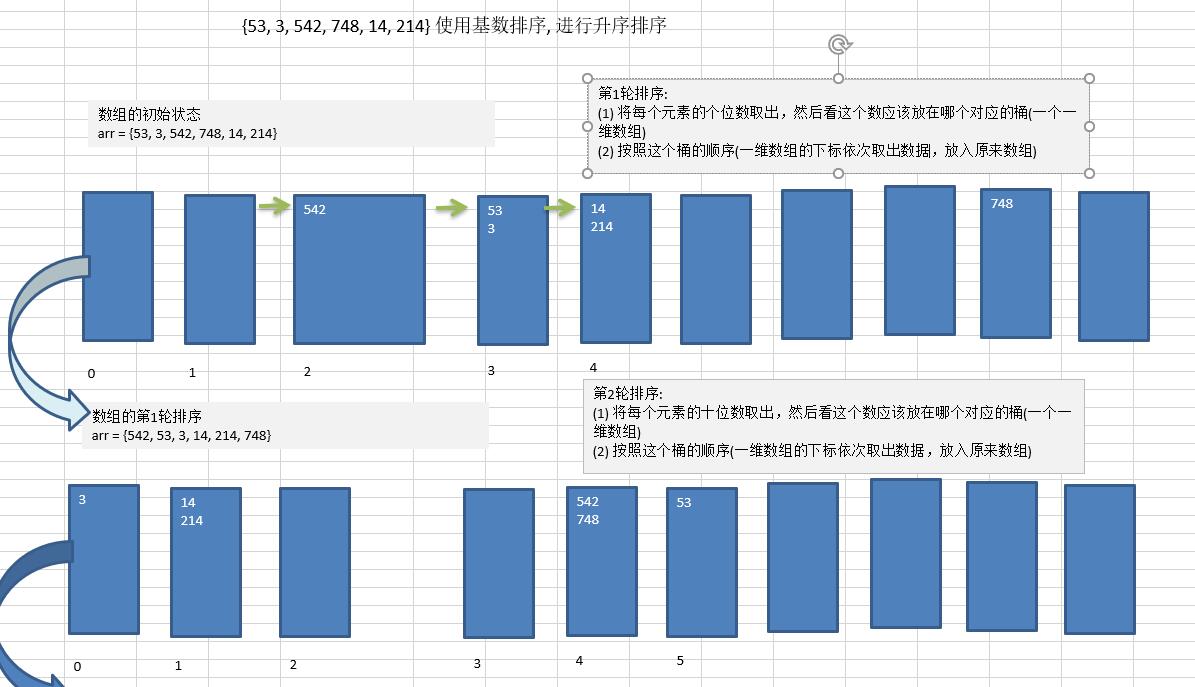
基数排序(RADIX-SORT)属于“分配式排序”,又称“桶子法”,顾名思义,它是通过键值的各个位的值,将要排序的元素分配至某些“桶”中,达到排序的效果。
基数排序是属于稳定性的排序,基数排序法是效率高的稳定性排序法
基数排序是桶排序的扩展。
基本思想
将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低为开始,依次进行排序。
这样从最低位排序一直到最高位排序完成以后,数列就是一个有序序列。
图文说明

代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| public static void radixSort(int[] arr) {
int max = arr[0];
for (int i = 0; i < arr.length; i++) {
if (arr[i] > max) {
max = arr[i];
}
}
int maxLength = (max + " ").length();
int[][] bucket = new int[10][arr.length];
for (int i = 0, n = 1; i < maxLength; i++, n \*= 10) {
int[] bucketElementCounts = new int[10];
for (int j = 0; j < arr.length; j++) {
int digitOfElement = arr[j] / n % 10;
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++;
}
int index = 0;
for (int k = 0; k < bucketElementCounts.length; k++) {
if (bucketElementCounts[k] != 0) {
for (int l = 0; l < bucketElementCounts[k]; l++) {
arr[index++] = bucket[k][l];
}
}
bucketElementCounts[k] = 0;
}
}
}
}
|
堆排序
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。
堆是什么?
具有完全以下性质的完全二叉树:每个节点的值都大于或等于其左右孩子节点的值,称为大顶堆,不要求节点的左孩子和右孩子值的大小。

每个节点的值都小于或等于其左右孩子节点的值,称为小顶堆
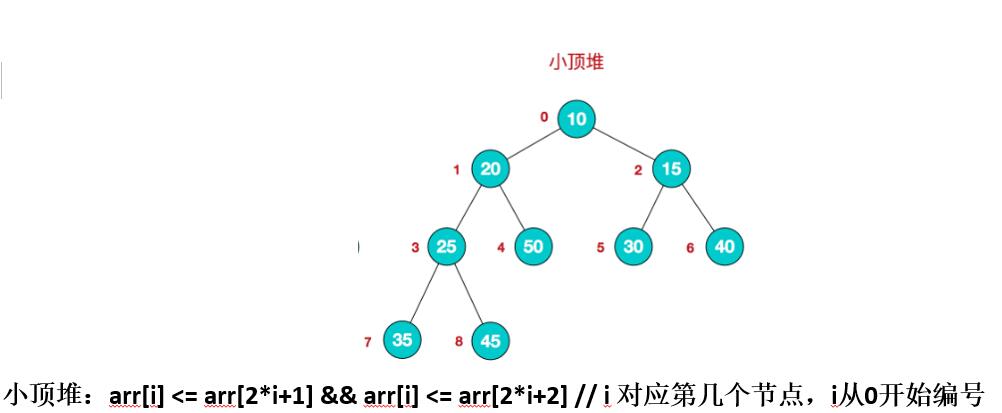
一般升序采用大顶堆,降序采用小顶堆
基本思想
- 将待排序序列构造成一个大顶堆
- 此时,整个序列的最大值就是堆顶的最大值
- 将其与末尾元素进行交换,此时末尾就为最大值
- 然后将剩下的n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,就得到一个有序序列了。
图解
步骤一:构造初始堆。将给定无序序列构造成一个大顶堆
1.假设给定无序序列结构如下
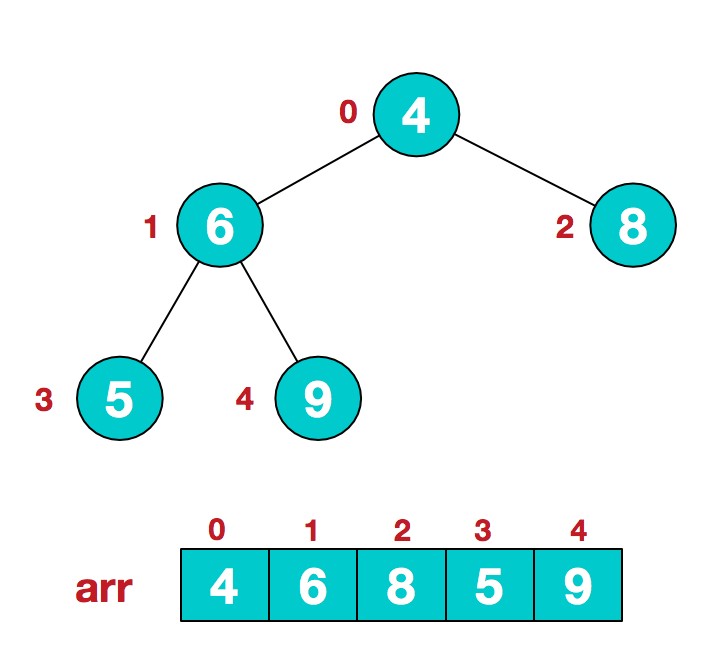
2.此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
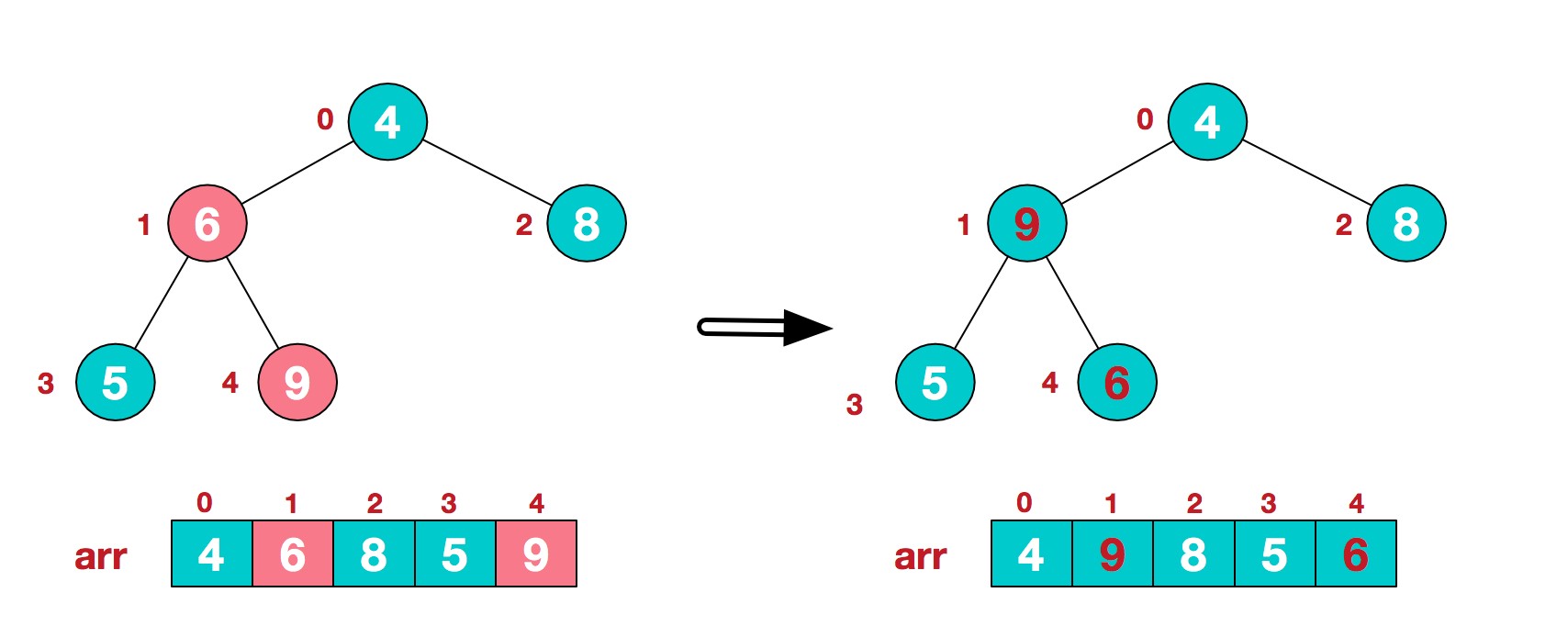
3.找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
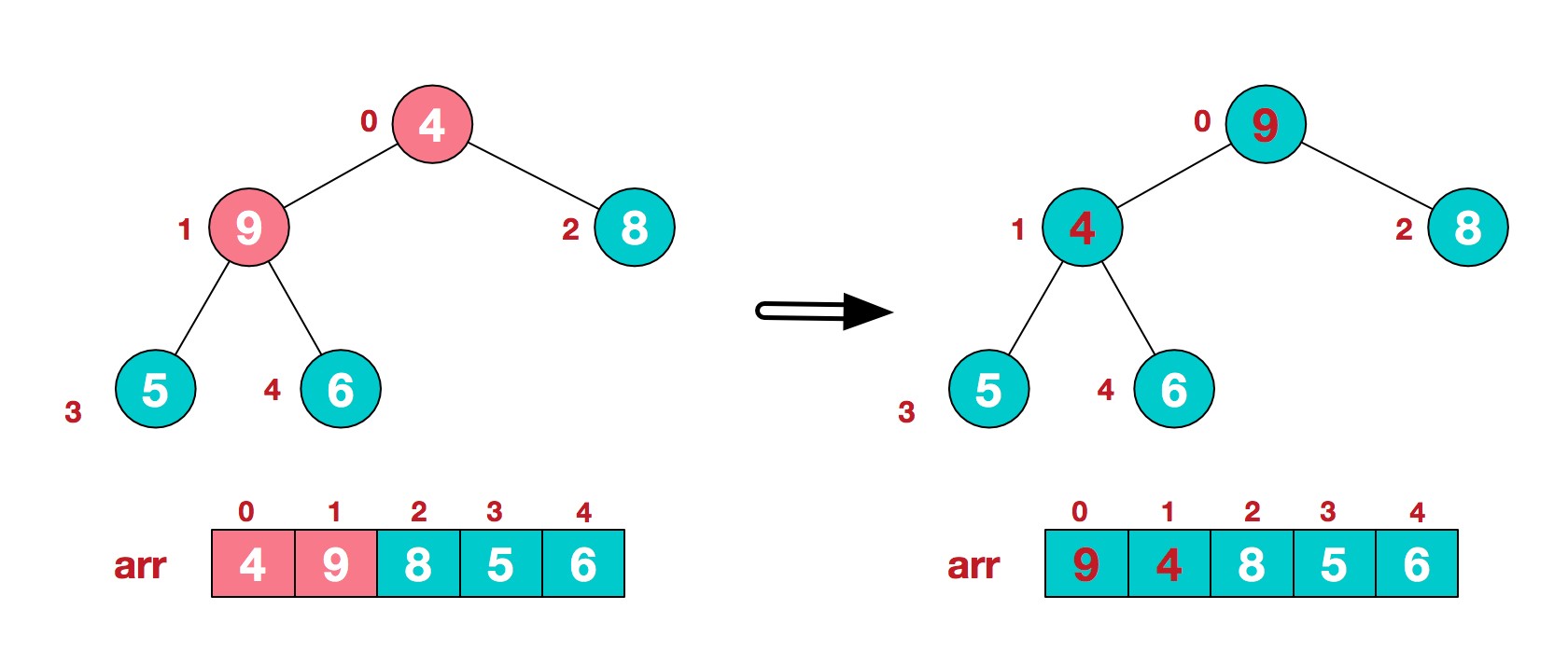
4.这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
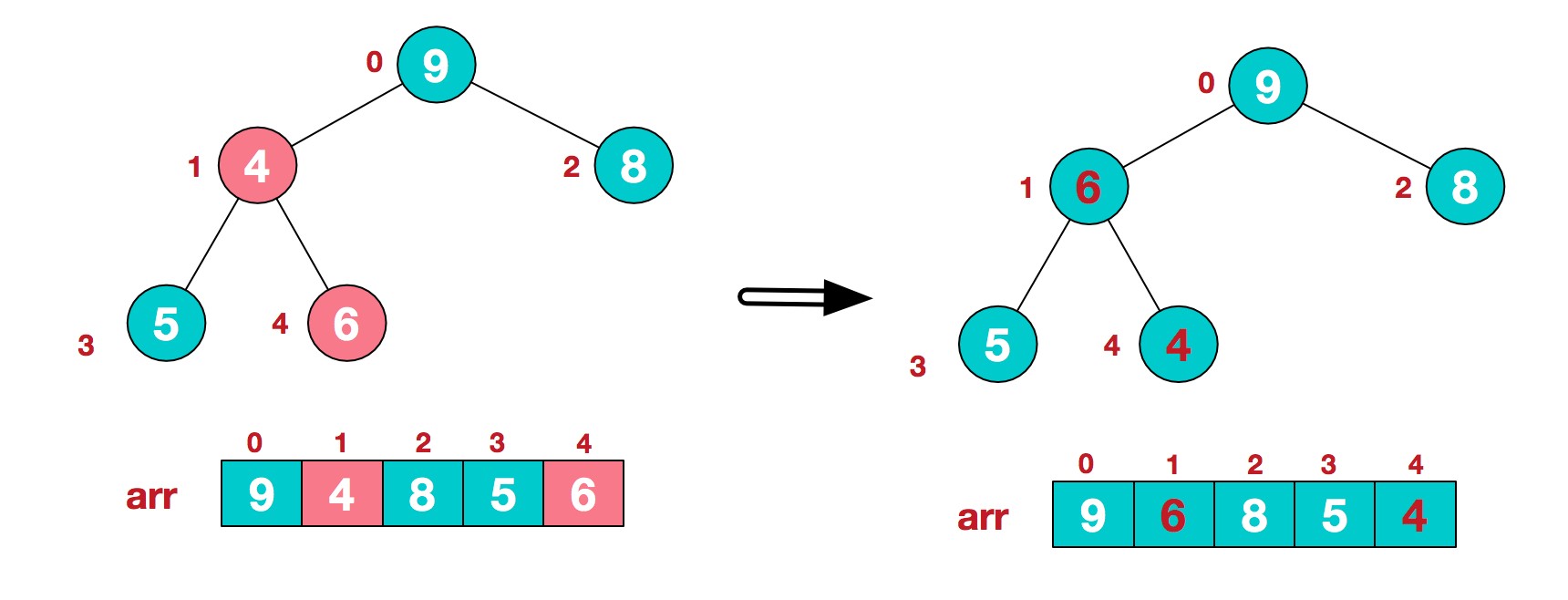
此时,我们就将一个无序序列构造成了一个大顶堆。
步骤二 :将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
6.将堆顶元素9和末尾元素4进行交换
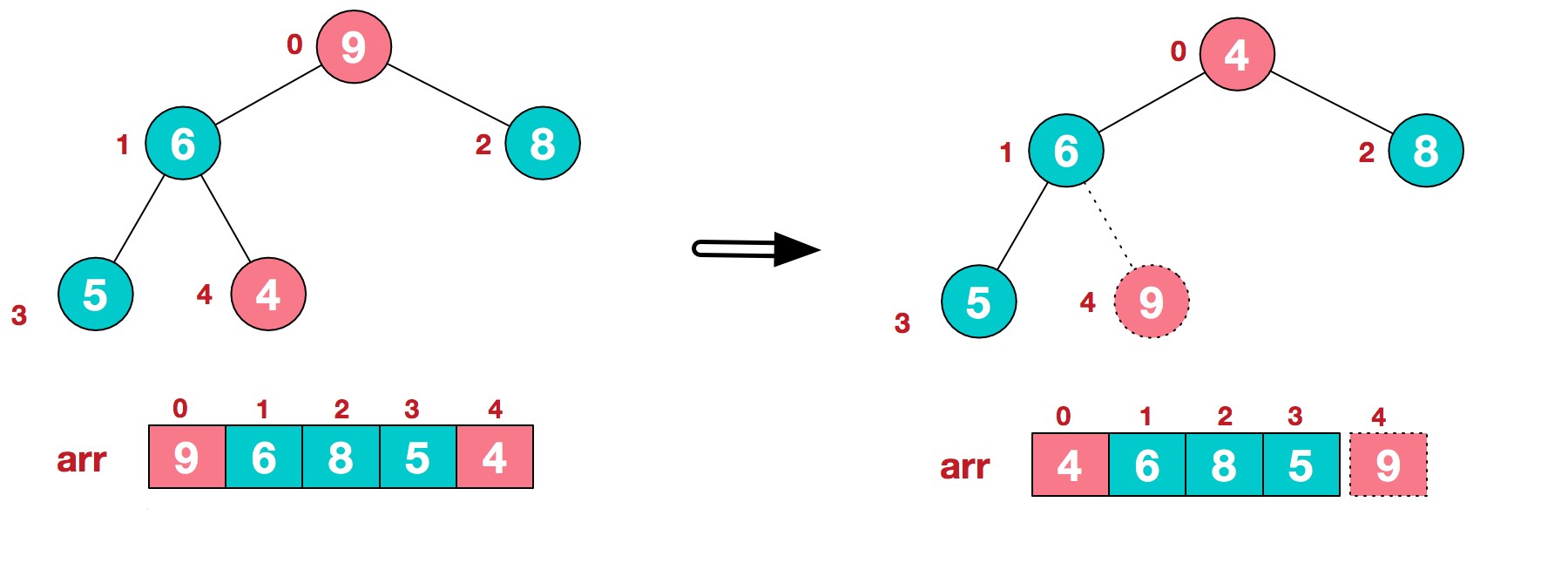
7.重新调整结构,使其继续满足堆定义
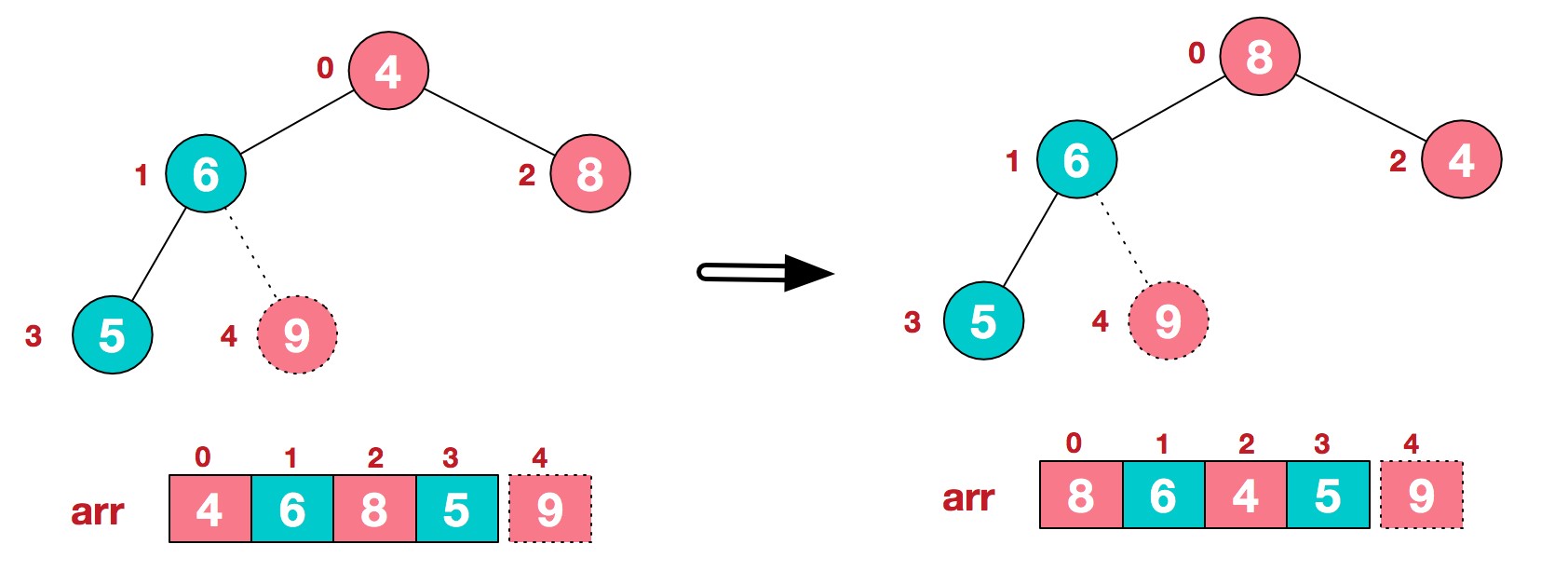
8.再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
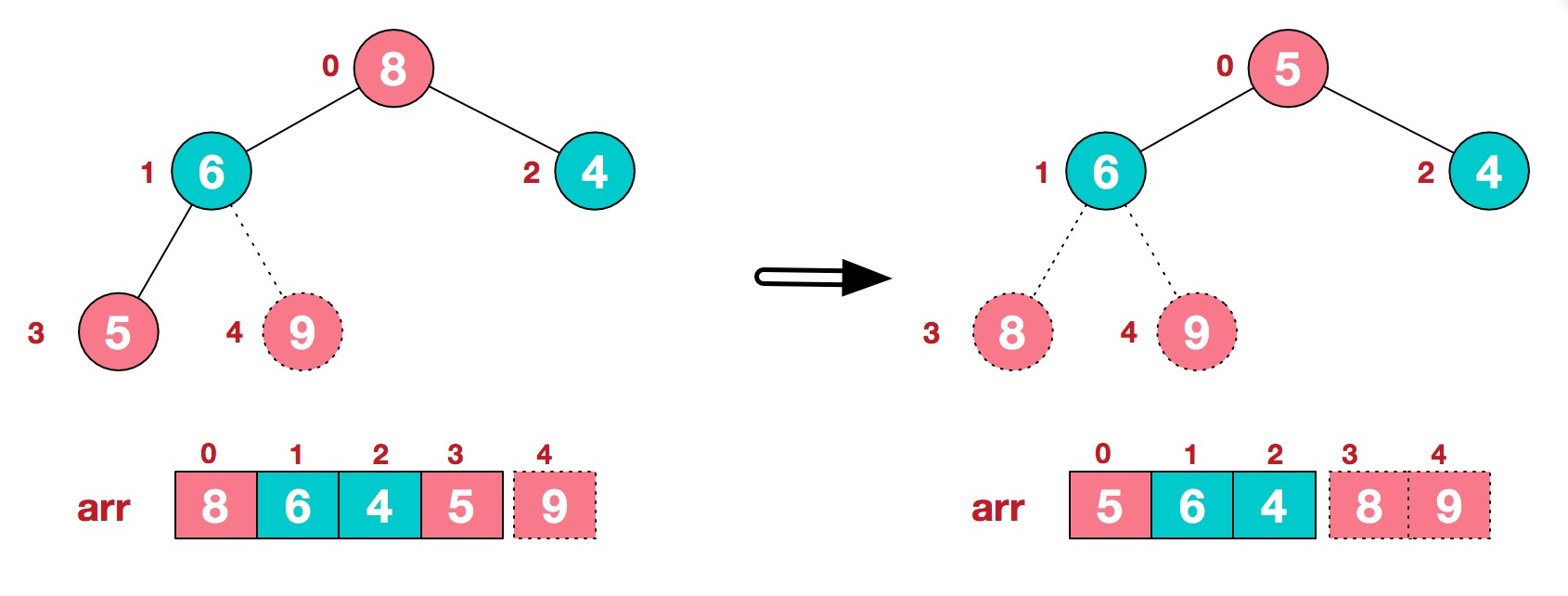
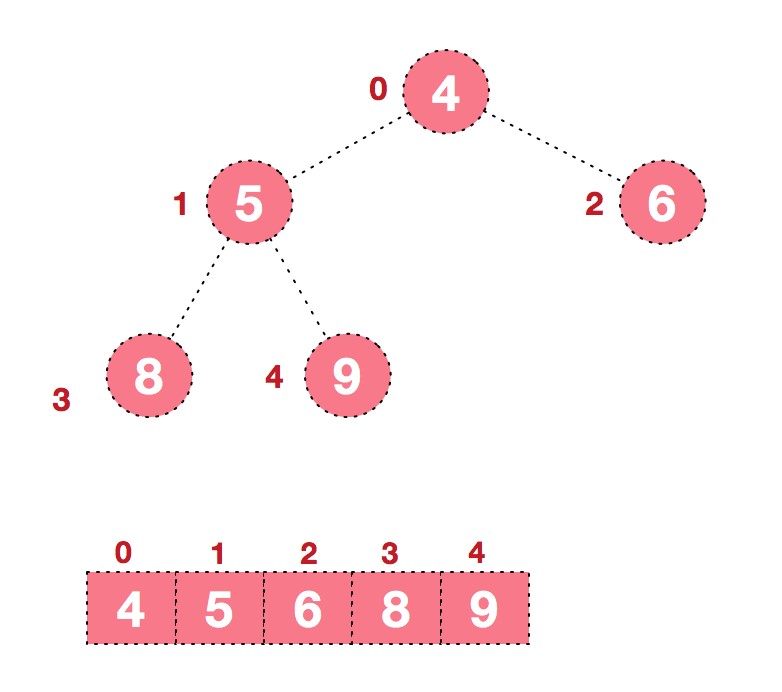
9.后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| public static void headSort(int arr []){
int temp = 0;
for (int i = arr.length /2 -1;i >=0;i --){
adjustHeap(arr,i,arr.length);
}
/\*\*
\* 2.将堆顶元素与末尾元素交换,将最大元素沉到数组末端
\* 3.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行
\*/
for (int j = arr.length -1; j > 0; j--){
temp = arr[j];
arr[j] = arr[0];
arr[0] = temp;
adjustHeap(arr,0,j);
}
}
/\*\*
\*
\* @param arr 待调整的数组
\* @param i 表示非叶子节点在数组中的索引
\* @param length 表示对多少个元素进行调整,length是在逐渐减少
\*/
public static void adjustHeap(int arr [],int i,int length){
int temp =arr[i];
for (int k = i \* 2 +1; k < length; k = i \* 2 +1) {
if (k+1 < length && arr[k] < arr [k+1]){
k ++;
}
if (arr [k] > temp){
arr[i] = arr [k];
i = k;
}else {
break;
}
}
arr [i] = temp;
}
}
|
这篇介绍是三种排序确定有点难,需要大家先理解实现思路,在debug进去程序,去看每一步的操作。
八大排序算法时间复杂度分析
| 排序算法 |
平均时间 |
最差情形 |
稳定度 |
额外空间 |
备注 |
| 冒泡 |
O(n^2) |
O(n^2) |
稳定 |
O(1) |
n小时较好 |
| 交换 |
O(n^2) |
O(n^2) |
不稳定 |
O(1) |
n小时较好 |
| 选择 |
O(n^2) |
O(n^2) |
不稳定 |
O(1) |
n小时较好 |
| 插入 |
O(n^2) |
O(n^2) |
稳定 |
O(1) |
大部分已排序较好 |
| 基数 |
O(logRB) |
O(logRB) |
稳定 |
O(n) |
B是真数(0-9)R是基数(个十百) |
| Shell |
O(nlogn) |
O(n^s) 1<s<2 |
不稳定 |
O(1) |
s是所选分组 |
| 快排 |
O(nlogn) |
O(n^2) |
不稳定 |
O(nlogn) |
n大时较好 |
| 归并 |
O(nlogn) |
O(nlogn) |
稳定 |
O(1) |
n大时较好 |
| 堆 |
O(nlogn) |
O(nlogn) |
不稳定 |
O(1) |
n大时较好 |
平均时间复杂度和最坏时间复杂度
平均时间复杂度是指所有可能的输入实例均以等概率出现的情况下,该算法的运行时间。
最坏情况下的时间复杂度称最坏时间复杂度。一般讨论的时间复杂度均是最坏情况下的时间复杂度。 这样做的原因是:最坏情况下的时间复杂度是算法在任何输入实例上运行时间的界限,这就保证了算法的运行时间不会比最坏情况更长。
我个人喜欢快排,尤其是递归实现的快排,理解思想和代码阅读都很容易,在开发中遇到排序通常调用的是集合工具类Arrays的sort()方法,它底层也是用的快排。