Mysql必知必会
介绍
MySQL 是最流行的关系型数据库管理系统,在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一。
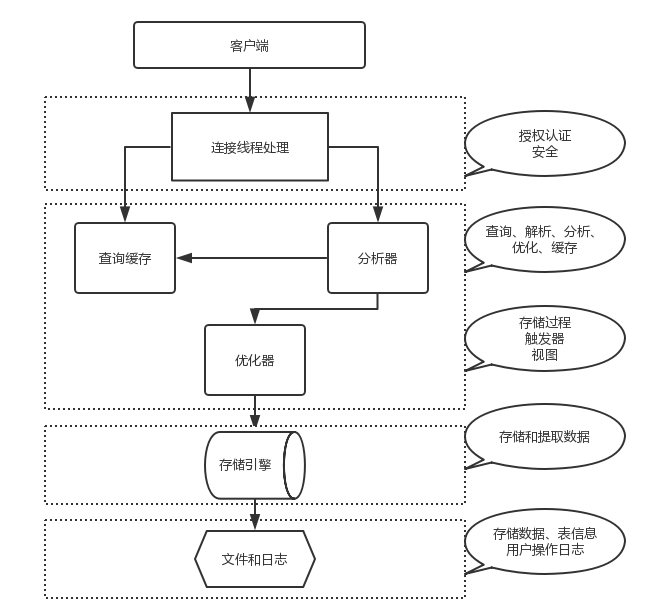
mysql架构图
myisam和innodb
myisam引擎是5.1版本之前的默认引擎,有如下特点:
不支持事务
只支持表级锁定 —>数据更新时锁定整个表,就说说对一个数据进行操作就会锁定整个表,其他人不能同时操作这个表,实现容易但并发效率低。
只会缓存索引 —> myisam可以通过key_buffer_size的值来提高缓存索引,以大大提高访问性能减少磁盘IO,但是这个缓存区只会缓存索引,而不会缓存数据。
读取速度较快,占用资源较少
不支持外键约束,但只是全文索引
对于count(*)查询来说MyISAM更有优势,因为其保存了行数
使用场景:
1.不需要支持事务的业务
2.读数据比较多的应用,读写都频繁的场景不适应(表级锁定)
3.独写并发访问较低的业务
innodb
- 支持事务,支持4个事务的隔离级别,支持多版本读
- 默认行级锁(更新时一般是锁定当前行),也支持表级锁。通过索引实现,全表扫描仍然会是表锁,需注意间隙锁的影响
- 具有非常高的缓存特性:缓存索引和数据
- 不支持全文索引,支持外键约束
- 通过MVCC支持高并发
- 基于聚簇索引创建
使用场景:
- 需要事务支持
- 行级锁对高并发有很好的适应能力,但需要确保查询是通过索引完成的
- 数据更新较频繁的场景
- 数据一致性要求高
- 硬件内存较大,可以提供很好的缓存效果
mysql的索引有哪些?聚簇索引和非聚簇索引是什么?
索引按数据结构来分主要包含:B+树和Hash索引
这里就不得不提下,为什么Mysql默认索引是B+树,不是B树?
- B+树是B树的变种,B+树的非叶子节点只用来保存索引,不存储数据,所有的数据都保存在叶子节点;而B树的非叶子节点也会保存数据。这样就使得B+树的查询效率更加稳定,均为从根节点到叶子节点的路径。
- B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相比B树更小,同样空间可以读入更多的节点,所以B+树的磁盘读写代价更低。
在Mysql文档里,实际上B+树索引写成了BTREE
1 | |
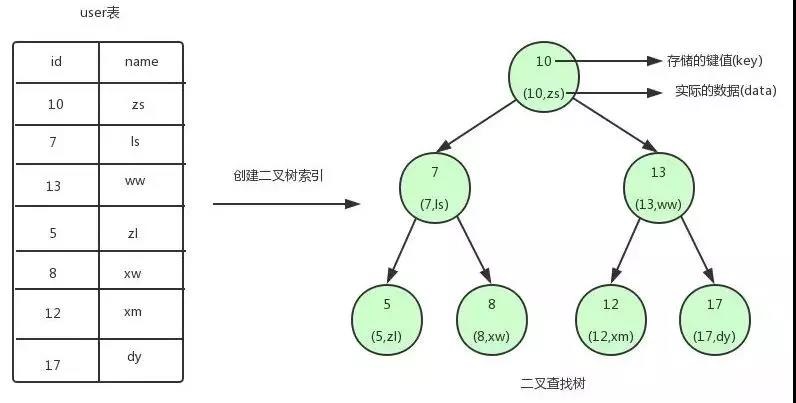
B+树是左小右大的顺序存储结构,节点只包含id索引列,而叶子节点包含索引列和数据,这种数据和索引在一起存储的索引方式叫做聚簇索引。非聚簇索引(二级索引)是在B+树的叶子节点上存储的数据,并不是数据本身,保存的是主键id值,这⼀点和myisam保存的是数据地址是不同的。。并且聚簇索引的数据的物理存放顺序与索引顺序是一致的,即只要索引是相邻的,那么对应的数据一定也是相邻的。聚簇索引要比非聚簇索引查询效率高很多。
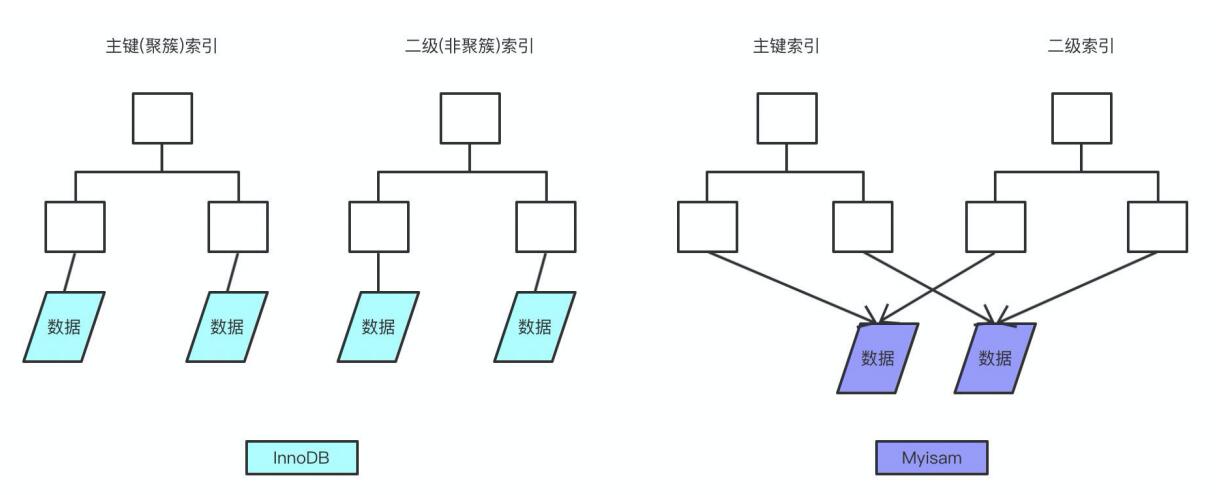
一张表只能有一个聚簇索引,因为物理地址是唯一确定的。假设没有定义主键,InnoDb会选择一个唯一的非空索引代替,如果没有的话则会隐式定义一个主键作为聚簇索引。
Hash索引
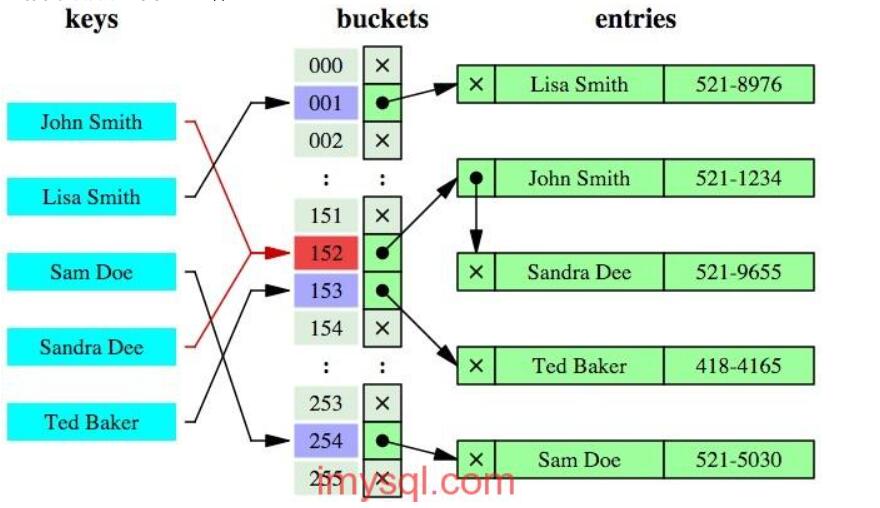
简单的说,Hash索引就说采用一定的Hash算法,把键值对换算成新的Hash值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
B+树索引和哈希索引的明显区别是:
如果是等值查询,那么哈希索引明显有绝对优势,因为只需要经过一次算法即可找到相应的键值;当然了,这个前提是,键值都是唯一的。如果键值不是唯一的,就需要先找到该键所在位置,然后再根据链表往后扫描,直到找到相应的数据;
从示意图中也能看到,如果是范围查询检索,这时候哈希索引就毫无用武之地了,因为原先是有序的键值,经过哈希算法后,有可能变成不连续的了,就没办法再利用索引完成范围查询检索;
同理,哈希索引也没办法利用索引完成排序,以及like ‘xxx%’ 这样的部分模糊查询(这种部分模糊查询,其实本质上也是范围查询);
哈希索引也不支持多列联合索引的最左匹配规则;
B+树索引的关键字检索效率比较平均,不像B树那样波动幅度大,在有大量重复键值情况下,哈希索引的效率也是极低的,因为存在的哈希碰撞问题。
覆盖索引和回表
覆盖索引是常见的SQL优化策略,指在一次查询中,如果一个索引包含或者说覆盖所有查询的字段值,我们就称为覆盖索引,而不需要回表查询。
回表是如何执行的呢?
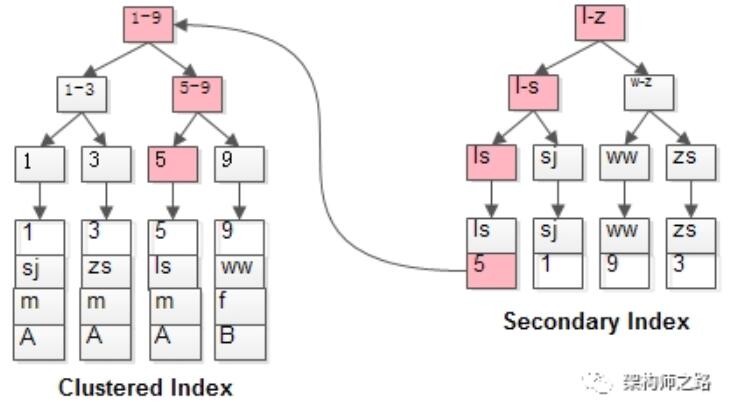
如粉红色路径,需要扫描两遍索引树:
- 先通过普通索引定位到id=5;
- 再通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫描一遍索引树慢。
确定⼀个查询是否是覆盖索引,我们只需要explain sql语句看Extra的结果是否是“Using index”即可。
1 | |
锁的类型
mysql锁分为共享锁和排他锁,也叫读锁和写锁。
读锁是共享的,可以通过lock in share mode 实现,这时候只能读不能写。
写锁是排他的,它会阻塞其他的写锁和读锁。从颗粒度来区分,可以分为表锁和行锁两种。
表锁会锁定整张表并且阻塞其他用户对该表的所有读写操作,比如alter修改表结构的时候就会锁表。
行锁又可分为乐观锁和悲观锁,悲观锁可以通过for update实现,乐观锁通过版本号实现。
事务的基本特性和隔离级别
mysql必问事务的!
事务基本特性ACID:
- 原子性(Atomicity):事务作为一个整体被执行,要么全部执行,要么全部不执行;
- 一致性(Consistrncy):保证数据库状态从一个一致状态转变为另一个一致状态。比如A转账给B100块,假设转成功,那么A和B在没进行转账之前的金额之和是等于转账成功现在的A和B的金额之和。假如中间sql执行过程中系统崩溃A也不会损失100块,因为事务没有提交,修改也不会保存到数据库中。
- 隔离性(ISolation):一个事务的修改在最终提交前,对其他事务是不可见的。
- 持久性(Durability):一个事务一旦提交,对数据库的修改是永久保存的。
四个隔离级别:
read uncommit 读未提交,可能读到其他事务未提交的数据,也叫脏读,举个栗子:用户A开启事务,修改自己的原来的age = 10为age = 20,但还未提交,用户B开启事务读取用户A的age,会发现读取的age = 20,但用户A的事务没提交,用户B去读取用户A的age应该是10,这就是脏读。
read commit 读已提交,两次读取结果不一致,叫做不可重复读。不可重复读解决了脏读的问题,但又出现个问题它只会读取已提交的事务。举个栗子,用户B在用户A尚未开启事务的时候去读取age = 10,但再次读取的时候A已经开启并提交事务,B再次读取A的时候age = 20,这就造成前后读的数据不一致。
repeatable read 可重复度,这是mysql的默认级别,就是每次读取结果都⼀样,但是有可能产⽣幻读。
serializable 串行,一般不使用,它会给每一行读取的数据加锁,会导致大量超时和锁竞争问题。
不做控制,多个事务并发操作数据库会出现什么问题?
- 丢失更新 两个事务同时获得相同的数据,然后在各自事务中同时修改了数据,谁先提交事务,谁的数据就会被后面提交事务的数据所覆盖,先提交的事务被后提交的所覆盖,导致数据更新失败。
- 脏读 事务A读取了事务B未提交的数据,由于事务B回滚,导致事务A读取了事务B未提交的数据,出现脏读。
- 不可重复读 一个事务在自己没更新数据库的情况,同一个查询操作执行两次或多次结果数值不一样,因为有别的事务更新了该数据,并且提交了事务。
- 幻读 事务A读的时候读出了N条记录,事务B在事务A执行的过程中增加了1条,事务A再读的时候就变成了N+1条,这种情况就叫做幻读。
注意:幻读是一种结构上的改变,比如数据条数的改变;不可重复读是读出的数值发生了改变。
ACID靠什么保证?
A原子性由undo log日志保证,它记录了需要回滚的日志信息,事务回滚撤销已经执行成功的SQL
C一致性一般由代码层面来保证
I隔离性由MVCC来保证
D持久性由内存+redo log(重做日志)来保证,mysql修改数据同时在内存和redo log记录这次操作,事务提交的时候通过redo log刷盘,宕机的时候可以从redo log恢复,这个能力称为crash-safe。
MVCC的是什么?
MVCC叫做多版本并发控制,实际上就是保存了数据在某个时间节点的快照。
我们每行数据实际上隐藏了两列,创建时间版本号,过期(删除)时间版本,每开始一个新的事务,版本号都会自动递增。
比如我们创建一个user表,字段为id,name,假如我们插入两条数据,它实际上长这样
| id | name | create_version | delete_version |
|---|---|---|---|
| 1 | 张三 | 1 | |
| 2 | 李四 | 2 |
假设这时候小明去执行查询,此时current_vision=3
1 | |
同时,小红在这个时候开启事务去修改id=1的记录,current_vision=4
1 | |
执行成功后的结果是这样的
| id | name | create_vison | delete_versin |
|---|---|---|---|
| 1 | 张三 | 1 | |
| 2 | 李四 | 2 | |
| 1 | 张三三 | 4 |
如果这时候还有小黑在删除id=2的数据,current_version=5,执行后结果是这样的。
| id | name | create_vison | delete_version |
|---|---|---|---|
| 1 | 张三 | 1 | |
| 2 | 李四 | 2 | 5 |
| 1 | 张三三 | 4 |
由于MVCC的原理是查找创建版本小于或等于当前事务版本,删除版本为空或者大于当前事务版本,小明真实的查询应该是这样的
1 | |
所以小明最后查询到的id=1的名字还是‘张三’,并且id=2也能查询到。这样做是为了保证事务读取的数据是在事务之前就已经存在的,要么是事务自己插入或者修改的。
明白MVCC原理,我们来说什么是幻读就简单多了。举一个常见的场景,用户在注册时,我们先查询用户名是否存在,不存在就插入,假设用户名是唯一索引。
小明开启事务current_version=6查询名字为’王五‘的记录,发现不存在。
小红开启事务current_version=7插入一条数据,结果是这样的:
| id | name | create_version | delete_version |
|---|---|---|---|
| 1 | 张三 | 1 | |
| 2 | 李四 | 2 | |
| 3 | 王五 | 7 |
- 小明执行插入名字’王五‘的记录,发现唯一索引冲突,无法插入,这就是幻读。
Mysql的日志模块redo log和binlog是什么?
在MySQL的使用中,更新操作也是很频繁的,如果每一次更新操作都根据条件找到对应的记录,然后将记录更新,再写回磁盘,那么IO成本以及查找记录的成本都很高。所以,出现了日志模块,即我们的update更新操作是先写日志,在合适的时间才会去写磁盘,日志更新完毕就将执行结果返回给了客户端。
MySQL中的日志模块主要有redo log(重做日志)和binlog(归档日志)。
redo log
redo log是InnoDB引擎特有的日志模块,redo log是物理日志,记录了某个数据页上做了哪些修改。InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么redolog总共就可以记录 4GB的操作。从头开始写,写到末尾就又回到开头循环写。
InnoDB的redo log保证了数据库发生异常重启之后,之前提交的记录不会丢失,这个能力称为crash-safe。
binlog
binlog是Server层自带的日志模块,binlog是逻辑日志,记录本次修改的原始逻辑,说白了就是SQL语句。binlog是追加写的形式,可以写多个文件,不会覆盖之前的日志。通过mysqlbinlog可以解析查看binlog日志。binlog日志文件的格式:statement,row,mixed。
- statement格式的binlog记录的是完整的SQL语句,优点是日志文件小,性能较好,缺点也很明显,那就是准确性差,遇到SQL语句中有now()等函数会导致不准确
- row格式的binlog中记录的是数据行的实际数据的变更,优点就是数据记录准确,缺点就是日志文件较大。
- mixed格式的binlog是前面两者的混合模式
业界目前推荐使用的是 row 模式,因为很多情况下对准确性的要求是排在第一位的。
在更新数据库的时候,通过redo log和binlog的两阶段提交,可以确保数据库异常崩溃之后数据的正确恢复。
在对数据库误操作之后,可以通过备份库+binlog可以将数据库状态恢复到“任意“时刻。
什么是间隙锁?
间隙锁是可重复读级别下才会有的锁,结合MVCC和间隙锁可以解决幻读的问题。我们还是以user举
例,假设现在user表有几条记录
| id | age |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
当我们执行:
1 | |
只有10可以插⼊成功,那么因为表的间隙mysql⾃动帮我们⽣成了区间(左开右闭)
1 | |
由于20存在记录,所以(10,20],(20,30]区间都被锁定了⽆法插⼊、删除。
如果查询21呢?就会根据21定位到(20,30)的区间(都是开区间)。
需要注意的是唯⼀索引是不会有间隙索引的。