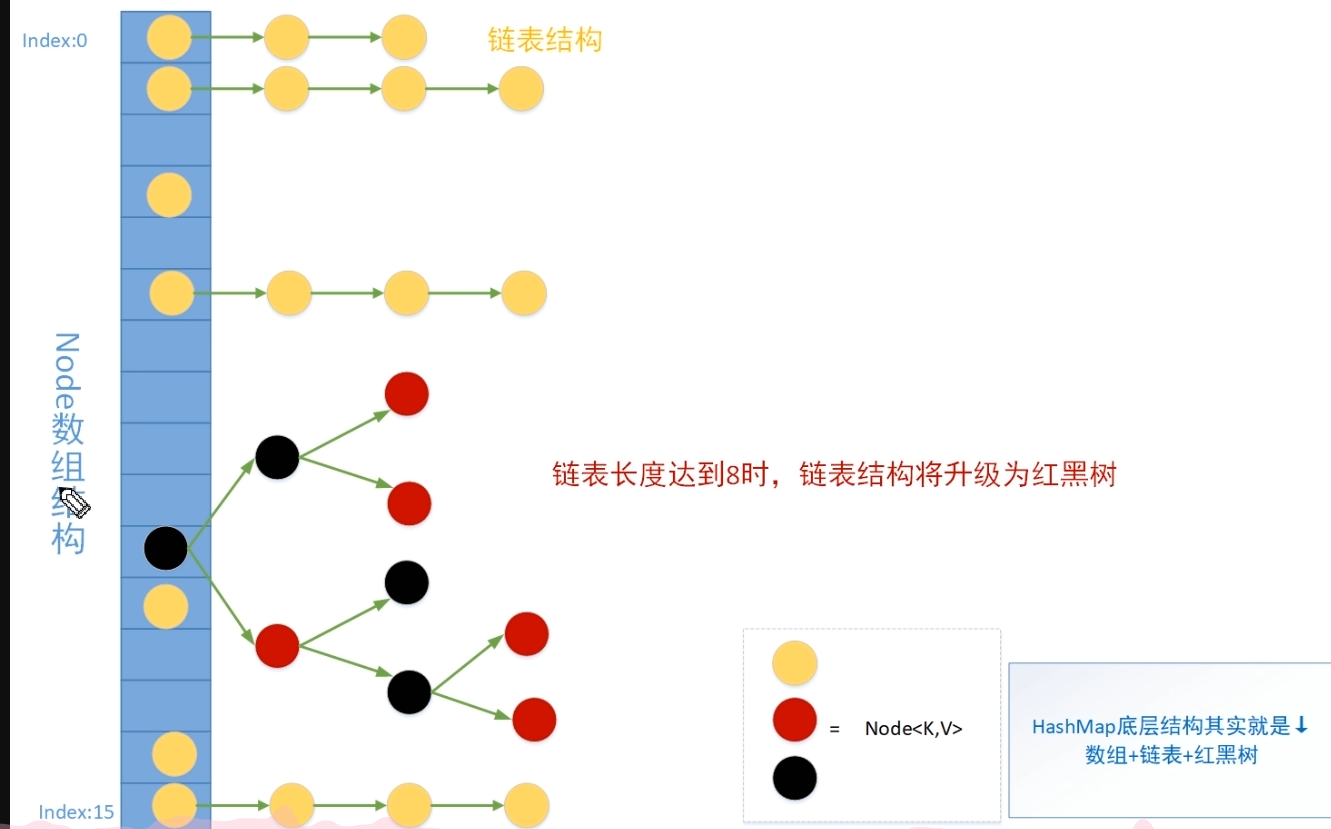
/\*\* \* The default initial capacity - MUST be a power of two. \* 默认的初始容量,必须是二的次方 \*/ staticfinalint DEFAULT\_INITIAL\_CAPACITY = 1 << 4; // aka 16 /\*\* \* The maximum capacity, used if a higher value is implicitly specified \* by either of the constructors with arguments. \* MUST be a power of two <= 1<<30. \* \* 最大容量,当通过构造函数隐式指定了一个大于MAXIMUM\_CAPACITY的时候使用 \*/ staticfinalint MAXIMUM\_CAPACITY = 1 << 30; /\*\* \* The load factor used when none specified in constructor. \* 加载因子,当构造函数没有指定加载因子的时候的默认值的时候使用 \*/ staticfinalfloat DEFAULT\_LOAD\_FACTOR = 0.75f; /\*\* \* The bin count threshold for using a tree rather than list for a \* bin. Bins are converted to trees when adding an element to a \* bin with at least this many nodes. The value must be greater \* than 2 and should be at least 8 to mesh with assumptions in \* tree removal about conversion back to plain bins upon \* shrinkage. \* \* TREEIFY\_THRESHOLD为当一个bin从list转化为tree的阈值,当一个bin中元素的总元素最低超过这个值的时候,bin才被转化为tree; \* 为了满足转化为简单bin时的要求,TREEIFY\_THRESHOLD必须比2大而且比8要小 \*/ staticfinalint TREEIFY\_THRESHOLD = 8; /\*\* \* The bin count threshold for untreeifying a(split) bin during a \* resize operation. Should be less than TREEIFY\_THRESHOLD, and at \* most 6 to mesh with shrinkage detection under removal. \* \* bin反tree化时的最大值,应该比TREEIFY\_THRESHOLD要小, \* 为了在移除元素的时候能检测到移除动作,UNTREEIFY\_THRESHOLD必须至少为6 \*/ staticfinalint UNTREEIFY\_THRESHOLD = 6; /\*\* \* The smallest table capacity for which bins may be treeified. \* (Otherwise the table is resized if too many nodes in a bin.) \* Should be at least 4 \* TREEIFY\_THRESHOLD to avoid conflicts \* between resizing and treeification thresholds. \* \* 树化的另外一个阈值,table的长度(注意不是bin的长度)的最小得为64。为了避免扩容和树型结构化阈值之间的冲突,MIN\_TREEIFY\_CAPACITY 应该最小是 4 \* TREEIFY\_THRESHOLD \*/ staticfinalint MIN\_TREEIFY\_CAPACITY = 64;
/\*\* \* The table, initialized on first use, and resized as \* necessary. When allocated, length is always a power of two. \* (We also tolerate length zero in some operations to allow \* bootstrapping mechanics that are currently not needed.) \* \* table,第一次被使用的时候才进行加载 \*/ transient Node<K,V>[] table; /\*\* \* Holds cached entrySet(). Note that AbstractMap fields are used \* forkeySet() and values(). \* 键值对缓存,它们的映射关系集合保存在entrySet中。即使Key在外部修改导致hashCode变化,缓存中还可以找到映射关系 \*/ transient Set<Map.Entry<K,V>> entrySet; /\*\* \* The number of key-value mappings contained in this map. \* table中 key-value 元素的个数 \*/ transientint size; /\*\* \* The number of times this HashMap has been structurally modified \* Structural modifications are those that change the number of mappings in \* the HashMap or otherwise modify its internal structure(e.g., \* rehash). This field is used to make iterators on Collection-views of \* the HashMap fail-fast. (See ConcurrentModificationException). \* \* HashMap在结构上被修改的次数,结构上被修改是指那些改变HashMap中映射的数量或者以其他方式修改其内部结构的次数(例如,rehash)。 \* 此字段用于使HashMap集合视图上的迭代器快速失败。 \*/ transientint modCount; /\*\* \* The next size value at which to resize(capacity \* load factor). \* \* 下一次resize扩容阈值,当前table中的元素超过此值时,触发扩容 \* threshold = capacity \* load factor \* @serial \*/ // (The javadoc description is true upon serialization. // Additionally, if the table array has not been allocated, this // field holds the initial array capacity, or zero signifying // DEFAULT\_INITIAL\_CAPACITY.(???????)) int threshold; /\*\* \* The load factor for the hash table. \* 负载因子 \* @serial \*/ finalfloat loadFactor;
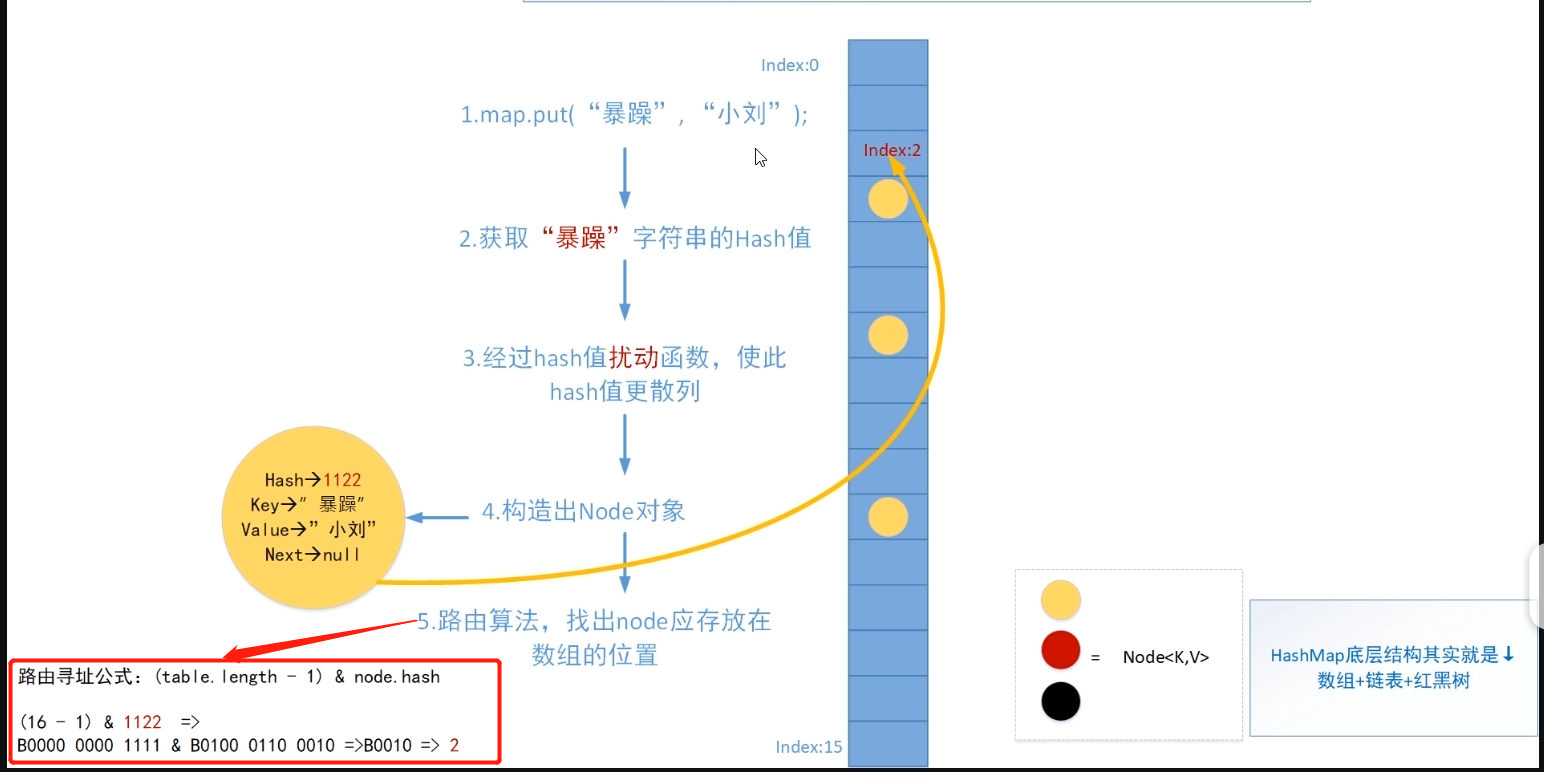
/\*\* \* @param key key with which the specified value is to be associated \* @param value value to be associated with the specified key \* @return the previous value associated with key, or \* nullif there was no mapping for key. \* (A nullreturn can also indicate that the map \* previously associated null with key.) \* 返回先前key对应的value值(如果value为null,也返回null),如果先前不存在这个key,那么返回的就是null; \*/ public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } / \* 在往haspmap中插入一个元素的时候,由元素的hashcode经过一个扰动函数之后再与table的长度进行与运算才找到插入位置,下面的这个hash()方法就是所谓的扰动函数 \* 作用:让key的hashCode值的高16位参与运算,hash()方法返回的值的低十六位是有hashCode的高低16位共同的特征的 \* 举例 \* hashCode = 0b 00100101101011000011111100101110 \* \* 0b 00100101101011000011111100101110 ^ \* 0b 00000000000000000010010110101100 \* 0b 00100101101011000001101010000010 \*/ staticfinalinthash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }